Semantic RAG Overview
Semantic RAG is an approach where a RAG assistant relies not only on vector similarity but also on a structured model of the domain. Vedana is an open-source implementation of Semantic RAG.
The four parts
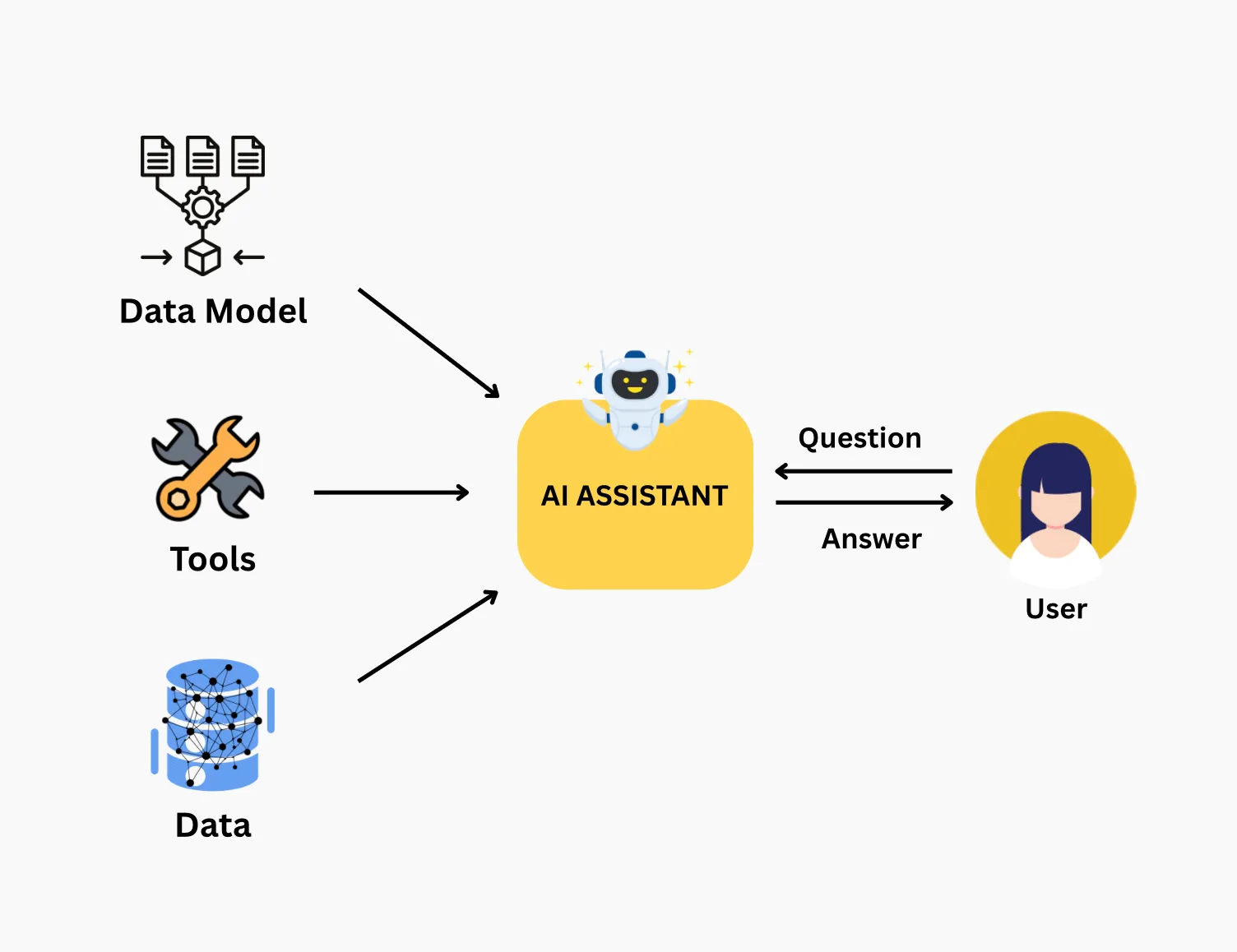
Any Semantic RAG system has four parts:
Data + Data Model + Tools + Assistant
- Data — documents and structured records. The thing you want to ask about.
- Data Model — a description of entities and the relationships between them. The thing that defines how the assistant sees your domain.
- Tools — operations (search, filter, count, traverse) that the assistant can invoke. The deterministic layer between the LLM and storage.
- Assistant — the LLM that picks tools, orchestrates them, and assembles the final answer.
Without that structure, the system guesses. With it, it can produce correct answers.
What this enables
The system can:
- return complete sets, not a sample;
- compute exact values, not approximations;
- evaluate relationships, not guess them;
- enforce domain logic, not approximate it.
How it works
At a high level:
- The user asks a question.
- The assistant identifies the question’s intent.
- The assistant picks the appropriate tool.
- The tool runs against the data.
- The assistant returns the result with sources.
In Vedana this unfolds as:
User → ThreadController → RagPipeline →
1) DataModelFiltering (optional, picks relevant anchors/links)
2) RagAgent with tools:
- vector_text_search (search over pgvector embeddings)
- cypher (Memgraph query)
3) The LLM assembles the final answer from the tool resultsRequired properties
A real Semantic RAG system must have:
- Deterministic execution — the same question triggers the same sequence of operations.
- Verifiable sources — every answer can be traced back to data.
- Guaranteed completeness — when the user asks for “all”, the system returns all of them, not a sample.
If any of those is missing, it’s still classic RAG in a fancy wrapper.
What Vedana does
Vedana implements Semantic RAG so that AI answers are:
- verifiable;
- aligned with real data and business logic.
Technically that means:
- a knowledge graph in Memgraph — anchors, attributes, links;
- a vector store in pgvector — embeddings for the attributes flagged
embeddable; - a data model — the description of anchors / links / queries / prompts in Grist, read at runtime;
- a playbook (query scenarios) — a set of steps the LLM should follow for typical intents;
- a LiteLLM wrapper — so you can switch providers without touching the code.
Next: Data Model for Vedana → Tools for Vedana → Playbook for Vedana.